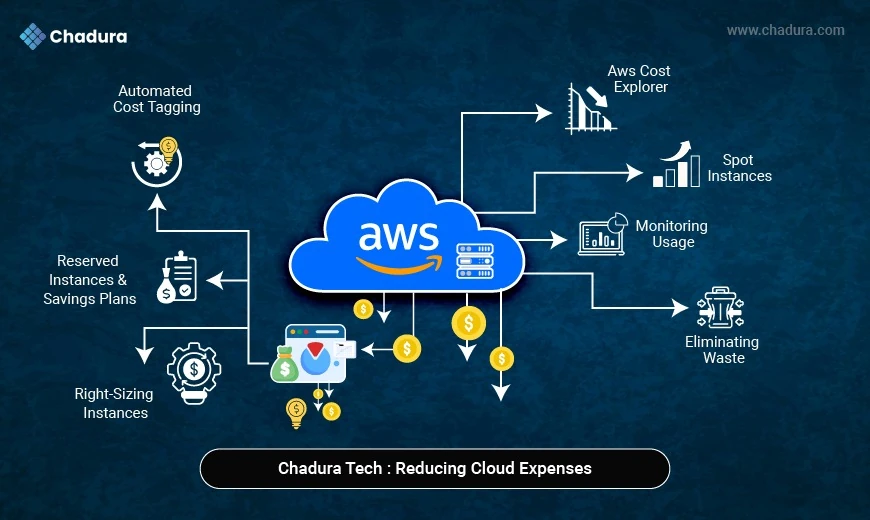
Introduction to AWS SageMaker
AWS SageMaker is a fully managed machine learning (ML) service provided by Amazon Web Services that allows developers and data scientists to build, train, and deploy machine learning models at scale. It abstracts the complexities involved in managing infrastructure, enabling fast experimentation and productionization of ML models.
SageMaker aims to provide an end-to-end machine learning platform that spans the entire ML lifecycle—from data labeling and preprocessing to training, evaluation, tuning, deployment, and monitoring.
Why Use SageMaker?
SageMaker addresses the typical pain points in ML development:
- Manual infrastructure setup
- Fragmented tools and services
- Lack of scalability
- Model monitoring and drift detection
- Reproducibility and auditability
Using SageMaker, businesses can:
- Reduce model development time
- Improve model performance
- Scale with ease
- Achieve enterprise-grade compliance and monitoring
Core Components and Architecture
High-Level Architecture
SageMaker provides modular components that can be used individually or as a fully integrated pipeline:
- SageMaker Studio: An integrated development environment for ML
- SageMaker Notebooks: Jupyter-based IDEs
- SageMaker Processing: For data transformation and preprocessing
- SageMaker Training: For model training using built-in or custom algorithms
- SageMaker Hyperparameter Tuning: For automated optimization
- SageMaker Inference: For model deployment, including real-time, batch, or serverless
- SageMaker Model Monitor: For detecting model drift and performance issues
Internal Services
- Amazon ECR: Stores container images
- Amazon S3: Stores datasets and models
- Amazon CloudWatch: Logs and monitoring
- IAM: Secure access control
- EFS and FSx: For high-speed file access
Key Features
- Built-in Algorithms and Frameworks: XGBoost, Scikit-learn, TensorFlow, PyTorch, HuggingFace
- Automatic Model Tuning: Hyperparameter optimization
- Pipelines and MLOps: CI/CD capabilities for ML
- JumpStart: Pre-trained models and example notebooks
- Data Wrangler: Simplified data preparation
- Clarify: Bias detection and explainability
- Ground Truth: Data labeling at scale
SageMaker Workflow Lifecycle
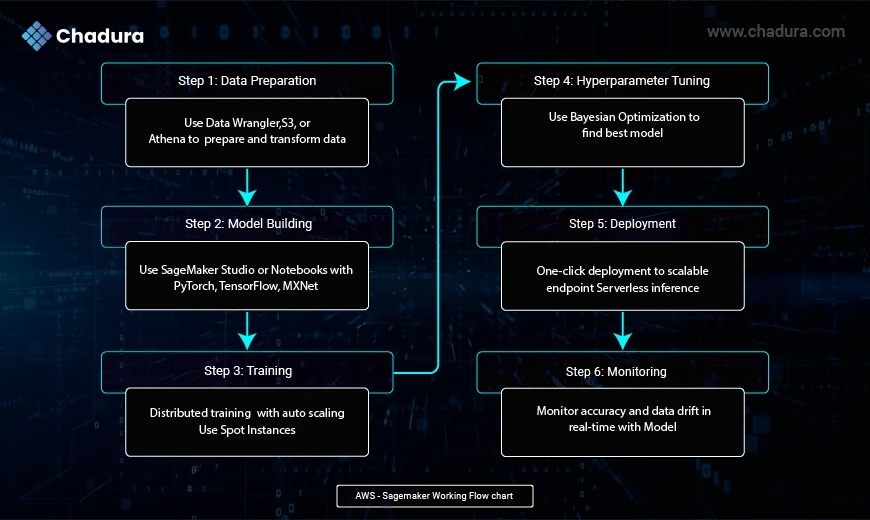
Step 1: Data Preparation
- Use Data Wrangler, S3, or Amazon Athena to prepare and transform data.
Step 2: Model Building
- Use SageMaker Studio or notebooks to build models using frameworks like PyTorch, TensorFlow, MXNet.
Step 3: Training
- Distributed training with automatic scaling
- Use spot instances to reduce costs
Step 4: Hyperparameter Tuning
- Find the best model using Bayesian optimization
Step 5: Deployment
- One-click deployment to a scalable endpoint
- Serverless inference available for spiky workloads
Step 6: Monitoring
- Monitor accuracy and drift in real-time using Model Monitor
6. Integration with Other AWS Services
- Amazon S3 – for data storage
- Amazon Athena – for querying data
- AWS Lambda – for automation
- AWS Step Functions – for orchestrating pipelines
- Amazon API Gateway – for exposing endpoints
- AWS Glue – for ETL processes
Aws - Sagemaker Features
- Fully Managed
- Scalability
- Cost Optimization
- Multi-Framework Support
- One-Click Deployment
- MLOps Integration
- Built-in Explainability
- Pre-built Models
- Security
- Compliance
Advantages:
- Reduces operational overhead
- Auto-scaling for training and inference
- Spot training instances
- TensorFlow, PyTorch, MXNet, HuggingFace
- Faster time to production
- SageMaker Pipelines and Model Registry
- Clarify for SHAP values
- JumpStart hub
- IAM, VPC, KMS support
- GDPR, HIPAA, SOC, ISO compliance
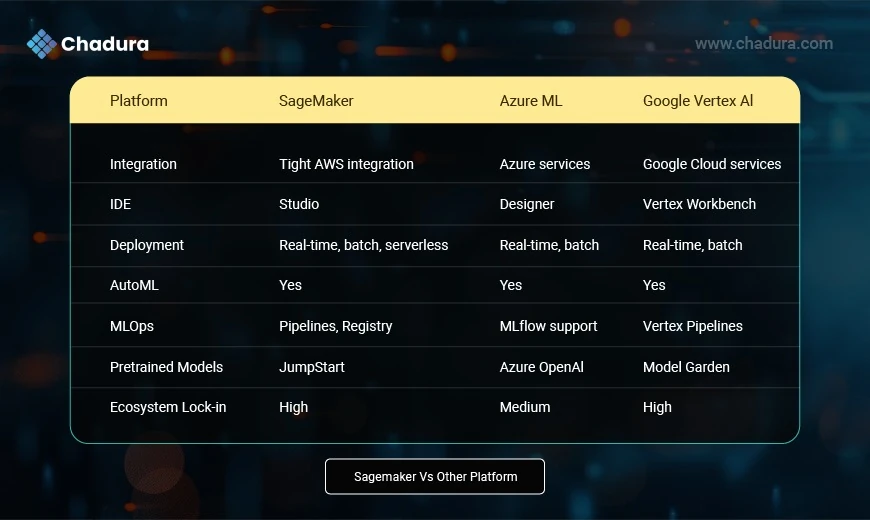
SageMaker vs. Other ML Platforms
Real-World Use Cases
Healthcare
- Predictive diagnostics
- Medical image classification
- Patient risk scoring
Finance
- Fraud detection
- Credit risk modeling
- Algorithmic trading
Retail
- Recommendation engines
- Dynamic pricing
- Inventory optimization
Manufacturing
- Predictive maintenance
- Quality inspection
Transportation
- Route optimization
- Fleet analytics
Security and Compliance
- IAM Policies: Fine-grained access
- PrivateLink/VPC: For secure network isolation
- Encryption: At rest and in transit (KMS)
- Audit Logs: Using AWS CloudTrail
- Compliance: HIPAA, GDPR, ISO, SOC, FedRAMP
Step-by-Step Workflow Explanation
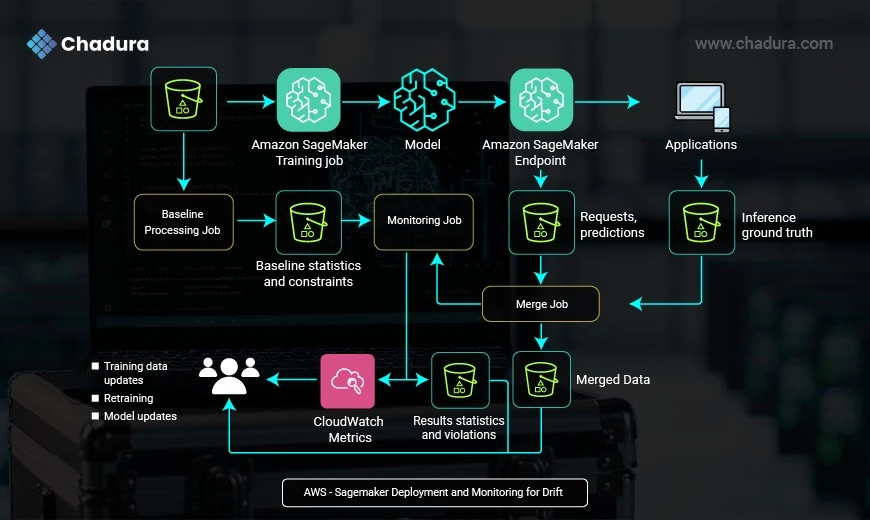
1. Model Training
- Input: Historical training data
- Action: An Amazon SageMaker Training Job is used to train a machine learning model.
- Output: A trained model artifact.
2. Baseline Processing Job
- Input: Same training data used in the model
- Action: A Baseline Processing Job analyzes training data to generate
- Baseline statistics (mean, std dev, distributions)
- Constraints (valid ranges, formats, anomalies)
- Output: These baselines act as reference standards for monitoring.
3. Model Deployment
- Action: The trained model is deployed to an Amazon SageMaker Endpoint (real-time inference service).
- Usage: Applications start sending real-time data to this endpoint for predictions.
4. Data Capture
- Input: Live requests and model predictions
- Also Input: Inference ground truth (if available from downstream applications)
- Action: Both are saved into S3 for analysis.
5. Merge Job
Action: Combines inference requests, predictions, and ground truth into a single merged dataset for evaluation.
6. Monitoring Job
- Action: A scheduled SageMaker Model Monitoring Job compares the merged data with the original baseline.
- Purpose: To detect:
- Data drift (changes in input distribution)
- Model drift (degraded prediction quality)
- Violations in expected behavior
7. CloudWatch Metrics
- Output: Statistics and violations are logged to Amazon CloudWatch.
- Trigger: These metrics can trigger alarms, dashboards, or automation pipelines.
8. Feedback Loop
- If drift or issues are detected:
- Data engineers and ML teams receive alerts
- Training data is updated
- Model is retrained
- A new version is deployed
Key Benefits
- Continuous quality check on ML models
- Automatic alerts for model degradation
- Scalable and production-ready workflow
- No need for manual monitoring
Final Thoughts
AWS SageMaker has emerged as a powerful and flexible tool for machine learning professionals and enterprises looking to accelerate their ML journey. While it comes with a learning curve and cost considerations, the operational simplicity, scalability, and deep integration with AWS services make it an ideal choice for organizations committed to AWS cloud.